Once upon a time...
When the ARPANET was designed in the late 1960s, it was outfitted with a Network Control Protocol (NCP) that made it possible for the very different types of hosts connected to the network to talk with each other. However, it soon became clear that NCP was limiting in some ways, so work started on something better. The engineers decided that it made sense to split the monolithic NCP protocol into two parts: an Internet Protocol that allows packets to be routed between the different networks connected to the ARPANET, and a Transport Control Protocol that takes a data stream, splits it into segments and transmits the segments using the Internet Protocol. On the other side, the receiving Transport Control Protocol makes sure the segments are put together in the right order before they're delivered as a data stream to the receiving application. An important implication of this approach is that unlike, for instance, a phone connected to a wired or wireless phone network, a host connected to the ARPANET then and the Internet now must know its own address.
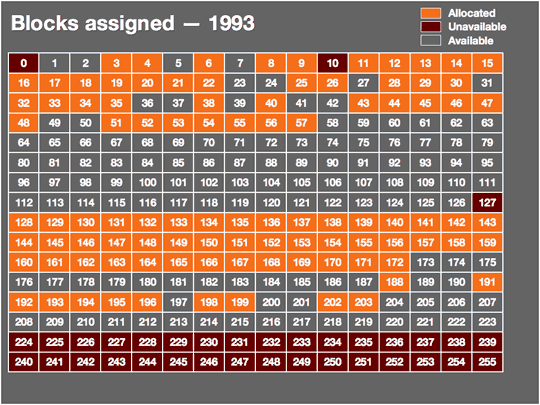
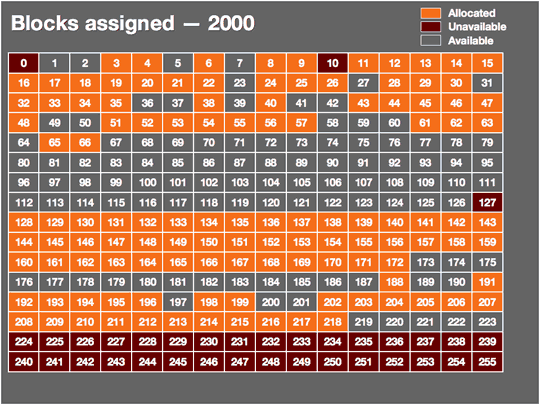
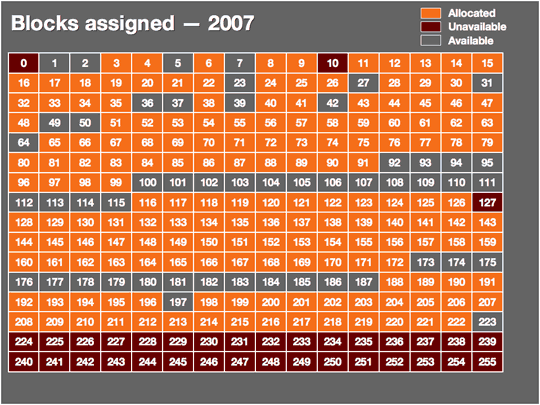
TCP/IP has served us well since it was born in 1981, but for some time now it has been clear that the IP part has a limitation that makes continued growth of the Internet for decades to come problematic. In order to accommodate a large number of hosts but not waste too much space in the IP packet on overhead, the TCP/IP designers settled on an address size of 32 bits. With 32 bits, it's possible to express 4,294,967,296 different values. Over half a billion of those are unusable as addresses for various reasons, giving us a total of 3.7 billion possible addresses for hosts on the Internet. As of January 1, 2007, 2.4 billion of those were in (some kind of) use. 1.3 billion were still available and about 170 million new addresses are given out each year. So at this rate, 7.5 years from now, we'll be clean out of IP addresses; faster if the number of addresses used per year goes up.
This is usually when someone brings up NAT. Home routers (and a lot of enterprise equipment) use a technique called "network address translation" so that a single IP address can be shared by a larger number of hosts. The discussion usually goes like this:
"Use NAT, n00b. All 1337 of my Linux boxes share a single IP and it's safer, too!"
"NAT is not a firewall."
"NAT sucks."
"You suck."
So what about NAT?
Hosts behind a NAT device get addresses in the 10.0.0.0, 172.16.0.0, or 192.168.0.0 address blocks that have been set aside for private use in RFC 1918. The NAT device replaces the private address in packets sent by the hosts in the internal network with its own address, and the reverse for incoming packets. This way, multiple computers can share a single public address. However, NAT has several downsides. First of all, incoming connections don't work anymore, because when a session request comes in from the outside, the NAT device doesn't know which internal host this request should go to. This is largely solvable with port mappings and protocols like uPnP and NAT-PMP.
IPv4 address ranges
- Class A: 1.0.0.1 to 126.255.255.254
- Class B: 128.1.0.1 to 191.255.255.254
- Class C: 192.0.1.1 to 223.225.254.254
- Class D: 224.0.0.0 to 239.255.255.255 — reserved for multicast groups
- Class E: 240.0.0.0 to 254.255.255.254 — reserved
Things get even trickier for applications that need referrals. NAT also breaks protocols that embed IP addresses. For instance, with VoIP, the client computer says to the server, "Please send incoming calls to this address." Obviously this doesn't work if the address in question is a private address. Working around this requires a significant amount of special case logic in the NAT device, the communication protocol, and/or the application. For this reason and a few others, most of the people who participate in the Internet Engineering Task Force (IETF) don't care much for NAT.
More to the point, NAT is already in wide use, and apparently we still need 170 million new IP addresses every year.
In the early days of the Internet, some organizations got excessively large address blocks. For instance, IBM, Xerox, HP, DEC, Apple and MIT all received "class A" address blocks of nearly 17 million addresses. (So HP, which acquired DEC, has more than 33 million addresses.) However, reclaiming those blocks would be a huge effort and only buy us a few more years: we currently burn through a class A block in five weeks. It's debatable how long we can make the IP address space last, especially as more and more devices, such as VoIP phones, become Internet-connected, but you can only keep squeezing the toothpaste tube for so long before it makes sense to buy a new one, even if the old one isn't technically empty. So in the early 1990s, the IETF started its "IP next generation" effort.
reader comments
4